Combine all parquet files in a directory
Published
Updated
This is the code I use to merge a number of individual parquet files into a combined dataframe. It will (optionally) recursively search an entire directory for all parquet files, skipping any that cause problems. It uses Pandas dataframes but it can easily be swapped out to use Dask if desired.
Here is an example of two parquet files I combined with the dataframe being written to a CSV file:
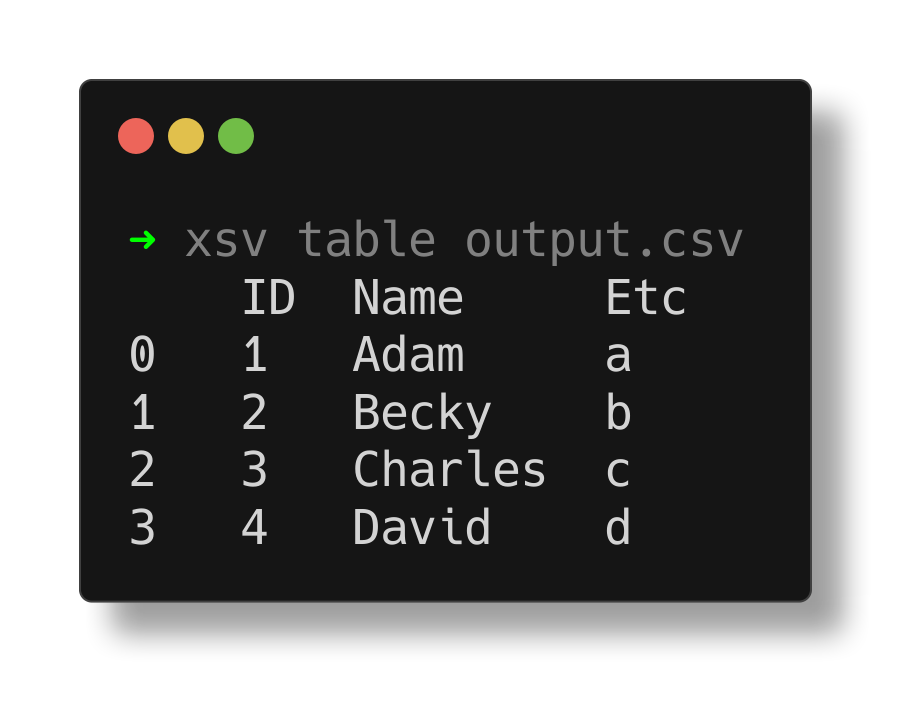
The following method will return a Dataframe loaded with all of the parquet files in a provided directory.
import glob, os
import pandas as pd
# Returns a dataframe that contains all of the directory's parquet files
def combine_directory_of_parquet(directory='./**/**.parquet', recursive=True, columns=[]):
# Create an empty dataframe to hold our combined data
merged_df = pd.DataFrame(columns=columns)
# Iterate over all of the files in the provided directory and
# configure if we want to recursively search the directory
for filename in glob.iglob(pathname=directory, recursive=recursive):
# Check if the file is actually a file (not a directory) and make sure it is a parquet file
if os.path.isfile(filename):
try:
# Perform a read on our dataframe
temp_df = pd.read_parquet(filename)
# Attempt to merge it into our combined dataframe
merged_df = merged_df.append(temp_df, ignore_index=True)
except Exception as e:
print('Skipping {} due to error: {}'.format(filename, e))
continue;
else:
print('Not a file {}'.format(filename))
# Return the result!
return merged_df
You can then reference it like so, assuming you have a subdirectory called my-parquet. It will then write the Dataframe to a CSV file.
# Replace this with your column names that you are expecting in your parquet's
columns = ['ID', 'Name', 'Etc']
# You can modify the directory path below, the asterisks are wildcard selectors to match any file.
df = combine_directory_of_parquet(directory='./my-parquet/**/**.parquet', recursive=True, columns=columns)
# Write the dataframe to a CSV file
df.to_csv('./output.csv')
# You can also write the dataframe as a parquet file like so:
#df.to_parquet('./combined.parquet')
You can use the below code to write some sample parquet data to read from for testing purposes:
data_a = {'ID': [1, 2], 'Name': ['Adam', 'Becky',], 'Etc': ['a', 'b']}
data_b = {'ID': [3, 4], 'Name': ['Charles', 'David'], 'Etc': ['c', 'd']}
df_a = pd.DataFrame(data_a)
df_b = pd.DataFrame(data_b)
df_a.to_parquet('./my-parquet/a.parquet')
df_b.to_parquet('./my-parquet/b.parquet')