Python - Read and write a file to S3 from Apache Spark on AWS EMR
Published
Updated
The following is an example Python script which will attempt to read in a JSON formatted text file using the S3A protocol available within Amazon’s S3 API. It then parses the JSON and writes back out to an S3 bucket of your choice. Please note this code is configured to overwrite any existing file, change the write mode if you do not desire this behavior.
from operator import add
from pyspark.sql import SparkSession
def main():
# Create our Spark Session via a SparkSession builder
spark = SparkSession.builder.appName("PySpark Example").getOrCreate()
# Read in a file from S3 with the s3a file protocol
# (This is a block based overlay for high performance supporting up to 5TB)
text = spark.read.text("s3a://my-bucket-name-in-s3/foldername/filein.txt")
# You can print out the text to the console like so:
print(text)
# You can also parse the text in a JSON format and get the first element:
print(text.toJSON().first())
# The following code will format the loaded data into a CSV formatted file and save it back out to S3
text.partition(1).write.format("com.databricks.spark.csv").option("header", "true").save(
path = "s3a://my-bucket-name-in-s3/foldername/fileout.txt", mode = "overwrite"
)
# Make sure to call stop() otherwise the cluster will keep running and cause problems for you
spark.stop()
main()
Running the code on an EMR Spark Cluster
I am assuming you already have a Spark cluster created within AWS. If not, it is easy to create, just click create and follow all of the steps, making sure to specify Apache Spark from the cluster type and click finish.
Next, upload your Python script via the S3 area within your AWS console.
In order to run this Python code on your AWS EMR (Elastic Map Reduce) cluster, open your AWS console and navigate to the EMR section. Click on your cluster in the list and open the Steps tab.
First, click the Add Step button in your desired cluster:
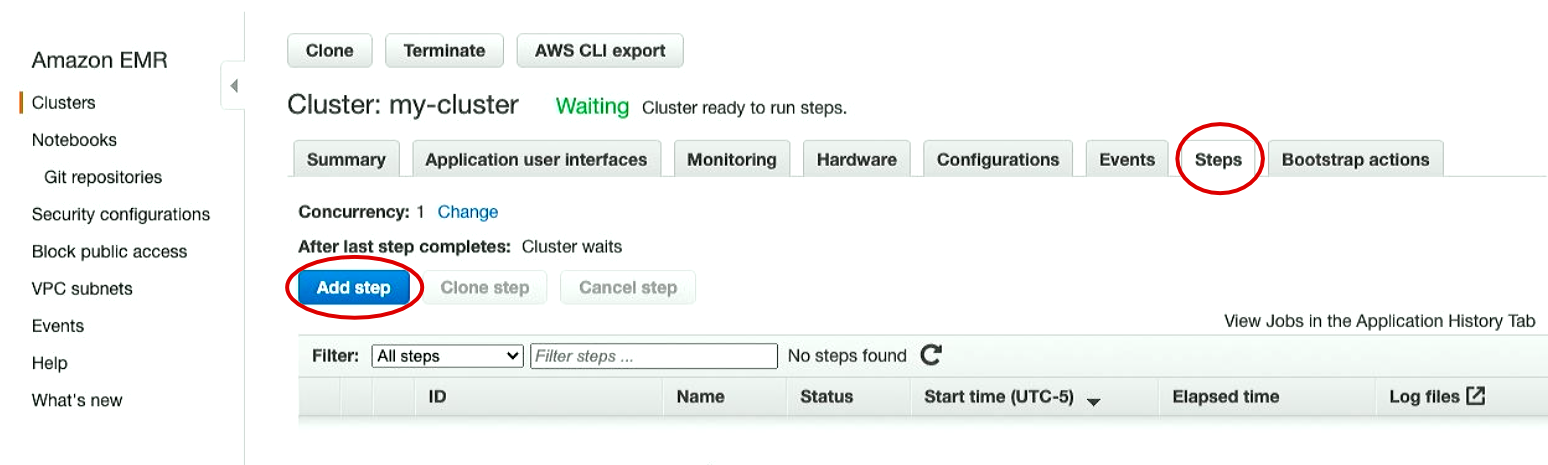
From here, click the Step Type from the drop down and select Spark Application.
Fill in the Application location field with the S3 Path to your Python script which you uploaded in an earlier step. Click the Add button.
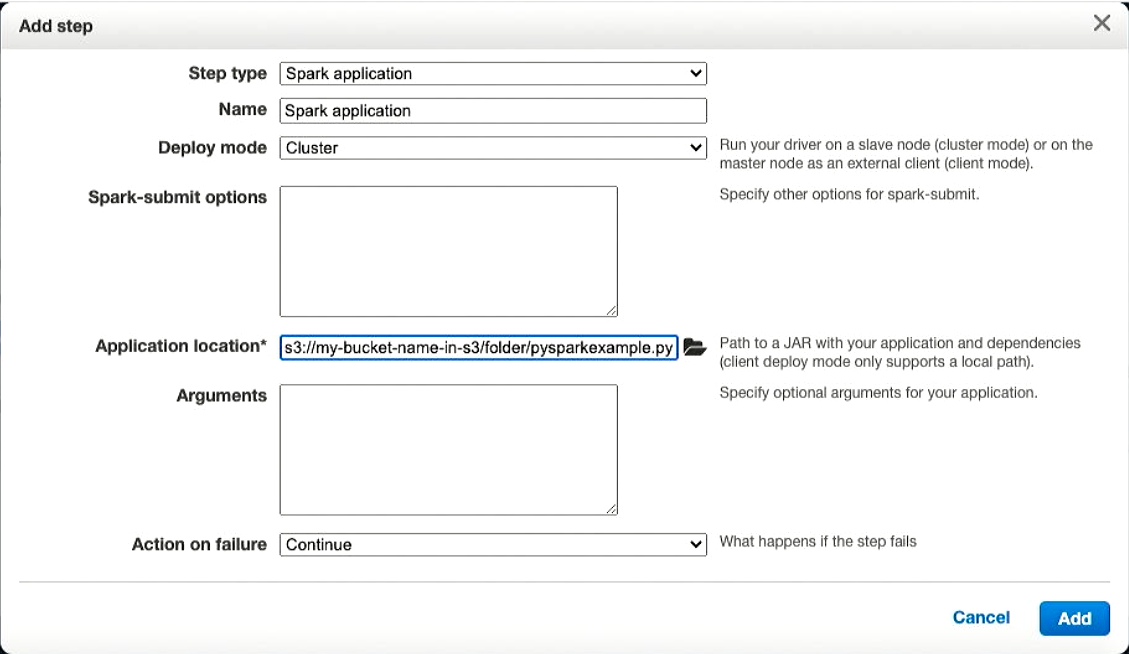
Your Python script should now be running and will be executed on your EMR cluster. Give the script a few minutes to complete execution and click the view logs link to view the results.